NTFS 파일 시스템
- New Technology File System
- FAT를 대체하기 위함
- 93년 윈도우 NT에서 최초로 도입
특징
1. 데이터 복구 기능: 모든 작업을 기록하고, 문제 발생 시 기록을 토대로 복원하는 기능
2. 암호화
3. 압축
4. ADS(Alternate Data Stream)
5. 대용량 지원: 이론상 264B까지 가능하나, 실제로 244B(16TB)까지 지원
MBR vs. GPT

MBR
- 처음 부분에 Master Boot Record와 Partition Entry를 가지고 있고, 뒤에 데이터를 가짐
GPT
- Protective MBR ( ) 뒤에 최대 128개의 Entry 공간이 있고, 각 파티션이 따라오고, 다시 엔트리 정보와 헤더가 존재함
- 즉, Primary GPT와 Secondary GPT를 가짐.
- 따라서, 한 쪽에서 데이터 손실 시 복구를 고려한 구조
- GPT는 MBR의 파티션 테이블 용량 한계를 보완하여 사용됨.
- GUID Partition Table
GPT 구조

LBA
- Logical Block Addressing, 논리 블록 주소 지정
- 컴퓨터 기억 장치에 저장되는 데이터 블록의 위치를 지정하는데 쓰이는 용어
- 여기서는 512 Bytes 단위로 사용됨
- 데이터 표기는 리틀 엔디안 사용

=> 리틀 엔디안의 경우, 0x40 E2 01 이 된다.
++ 사용 함수: Int.from_bytes(data, byteorder='little')
LBA 0 (Protective MBR)
- 일반 MBR에서 실수로 데이터를 변경하지 않도록 오프셋 0x01C2 자리에 b'\xEE'라고 표기하여 사용 중임을 표시하고, 나머지 대부분의 자리는 비워둠
- 걍 기본 MBR과 호환하기 위함이라 생각하면 됨.
- 오프셋 0x01FE~0x01FF 자리에는 시그니처인 b'\x55\xAA' 를 기록함
++ b'~~~' 는 그냥 1byte 자료형이라고 생각하면 됨. 리틀 엔디안으로 저장된 바이트 모습
LBA 1 (GPT Header)
- 실질적인 GPT 헤더 역할



- Signature: 본 시스템이 UEFI에 바탕을 둔 시스템임을 확인
- 해당 데이터가 있는 위치: LBA 1
- 파티션 엔트리가 LBA 2에서 시작
- 엔트리 최대 개수: 128
- 각 엔트리 크기: 128 Bytes
=> LBA 2로 이동하여 엔트리에 들어있는 데이터를 확인 가능하다.
LBA 2 ~ 33 (Entries)
- 각 엔트리 크기가 128 Bytes라고 했으니, 각 LBA는 4개의 엔트리를 가지게 됨 (128 * 4)
- 따라서, 128개의 엔트리에 할당된 LBA는 32개 (128 / 4)
- 즉, LBA 2 ~ 33까지 보면 된다.


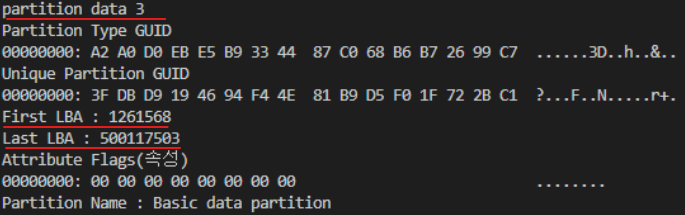
- First LBA: 해당 파티션이 시작되는 위치
- Last LBA: 해당 파티션이 끝나는 위치
- 각 파티션은 할당된 구간의 LBA를 사용함. 즉, 파티션 3은 LBA 1261568 ~ 500117503을 할당 받아 사용함.
- 현재 파티션 3을 C드라이브로 사용하고 있음 (...? 파티션명이 Basic data partition이라서 그런가 ...?)
- 따라서 해당 드라이브 내부 자료를 확인하기 위해서는 LBA 1261568로 이동하면 됨.
Tools
1. WinHex
2. VSCode
3. HexDump
- Python 3 라이브러리
- !pip install hexdump 명령어로 설치한 후, 코드 내에서 import하여 사용

- 변수 data는 16진수 형태의 바이너리 파일로, 위의 예시처럼 hexdump.hexdump() 함수 안에 바이너리 데이터를 입력하면, 아래와 같이 출력됨.

사용한 함수들
1. open() : 하드디스크의 정보를 불러오는데 사용함. 바이너리 데이터로 불러오기 위해, reading + binary를 합쳐 rb라고 표기하여 정보를 불러옴
2. seek() : read() 에서 자료를 읽기 위해, 자료의 시작 지점을 입력하는 함수
3. read() : 입력받은 숫자만큼의 데이터를 읽는 함수로, 최소 단위로 1개의 LBA 즉 512 bytes가 적절하기에 512 입력하여 사용함
4. chr() : 출력하고자 하는 결과가 이름인 경우, 입력받은 값들을 아스키 등으로 바꾸기 위해 사용함
5. join() : chr() 로 문자로 바꾼 것들을 한 문자열로 합치기 위해 사용
6. Int.from_bytes(data, byteorder='little') : data 자리에 바이트 값을 입력하면 리틀 엔디안으로 계산하여 정수로 출력해주는 함수
참고
https://nurilab.github.io/2022/12/07/ntfs1/
NTFS 파일 시스템
연재 순서 첫번째 글: NTFS 파일 시스템 두번째 글: NTFS 파일 시스템 partition data 1 세번째 글: NTFS 파일 시스템 partition data 2 네번째 글: 드라이브 내 파일 탐색 1. 분석 목적 NTFS 시스템의 특징을 이해
nurilab.github.io
'etc.' 카테고리의 다른 글
| [Discord] 봇 실행 테스트 (0) | 2023.01.16 |
|---|---|
| [Discord] 봇, 토큰 생성 (0) | 2023.01.14 |
| [기술 스터디] 02. 클라우드의 시작과 끝, 클라우드 보안 (0) | 2022.11.02 |
| [기술 스터디] 01. NSIS형태의 LockBit 3.0 랜섬웨어 (0) | 2022.10.05 |
| Jupyter Notebook / AES-128 구현 (0) | 2022.04.13 |