
문제에서 얻은 pdf 파일을 열면, 위와 같은 이미지를 볼 수 있다.
이외에는 딱히 알 수 있는 게 없어서,
우선, PDF 파일의 구조에 대해 알아보려고 한다.

1. PDF Header
2. Body
3. Cross Reference Table
4. Trailer
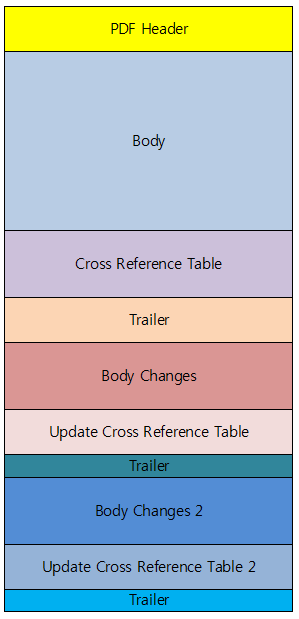
문제에서 주어진 파일을 HxD로 열어서 PDF 구조에 대해 알아보자.
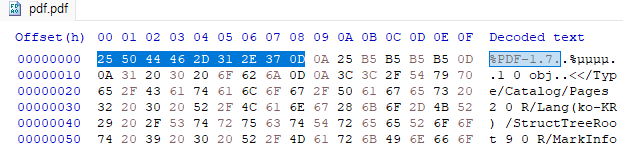
1. Header
- 총 8바이트로 PDF 시그니처와 PDF 문서의 버전 정보를 포함함
- PDF 시그니처인 25 50 44 46 을 확인할 수 있음
- 1.7 버전이라는 것을 확인할 수 있음

2. Body
- 실제 문서의 정보들을 포함하는 오브젝트들로 구성되고, 이 오브젝트들은 트리 형태로 링크되어 있음
- 오브젝트의 유형: Boolean, Numeric, String, Name, Array, Dictionary, Stream, Indirect 등
- 1 0 obj 로 1번 오브젝트의 시작을 표시하는 부분을 확인할 수 있음
- endobj 로 1번 오브젝트의 끝을 표시하는 부분을 확인할 수 있음

3. Xref Table
- 각 오브젝트들을 참조할 때 사용되는 테이블로, 오브젝트의 사용 여부와 식별 번호 등이 저장되어 있음
- xref 뒤의 0 36 으로 해당 파일이 총 36개의 오브젝트를 가지고 있음을 알 수 있음

4. File Trailer
- File Body에 존재하는 오브젝트들 중 최상위 오브젝트가 무엇인지, Xref Table이 어디에 위치하는지 기록됨
- %%EOF 로 파일의 끝을 나타내고 있음
이제 문제를 해결해보자 !!
PDF는 사진 파일을 전처리 없이 내부에 원본 그대로 삽입한다고 한다.
즉, PDF 파일에 JPG 파일이 있으면, JPG Header부터 Footer까지 데이터가 존재한다는 뜻이다.
따라서 exploit이 써져 있는 원본 사진 파일을 PDF 파일 내부에 그대로 보관한다고 할 수 있다.
JPG 파일의 Header 시그니처 FF D8 FF E0 와 Footer 시그니처 FF D9 을 찾아서 삭제하고, 다시 저장했더니 ...

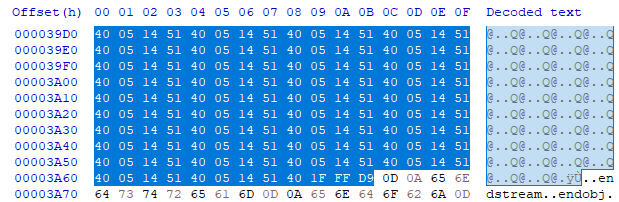

플래그를 얻을 수 있었다.
즉, exploit 이미지가 플래그 부분을 가리고 있었고, 해당 이미지를 삭제해줌으로써 문제를 해결할 수 있었다.
참고
'Forensic > wargame & ctf' 카테고리의 다른 글
| [HackCTF] 나는 해귀다 (0) | 2022.01.15 |
|---|---|
| [HackCTF] 잔상 (0) | 2022.01.06 |
| [HackCTF] Question? (0) | 2022.01.06 |
| [HackCTF] Secret Document (0) | 2021.11.21 |
| [HackCTF] So easy? (0) | 2021.11.09 |



